Client/Server Model#
Typically, the software you're running on your local system, such as a web browser like Firefox, is called a client. The client makes connections from your local system to remote systems to request information. In the case of Firefox that connection is set up using TCP and is then used to request web sites.
Visually, the client/server model is very simple, but there are some key bits of information you need to know about today so you can understand the more complex networking (security) concepts later on.
Here's what the client/server model looks like, along with those extra little details:
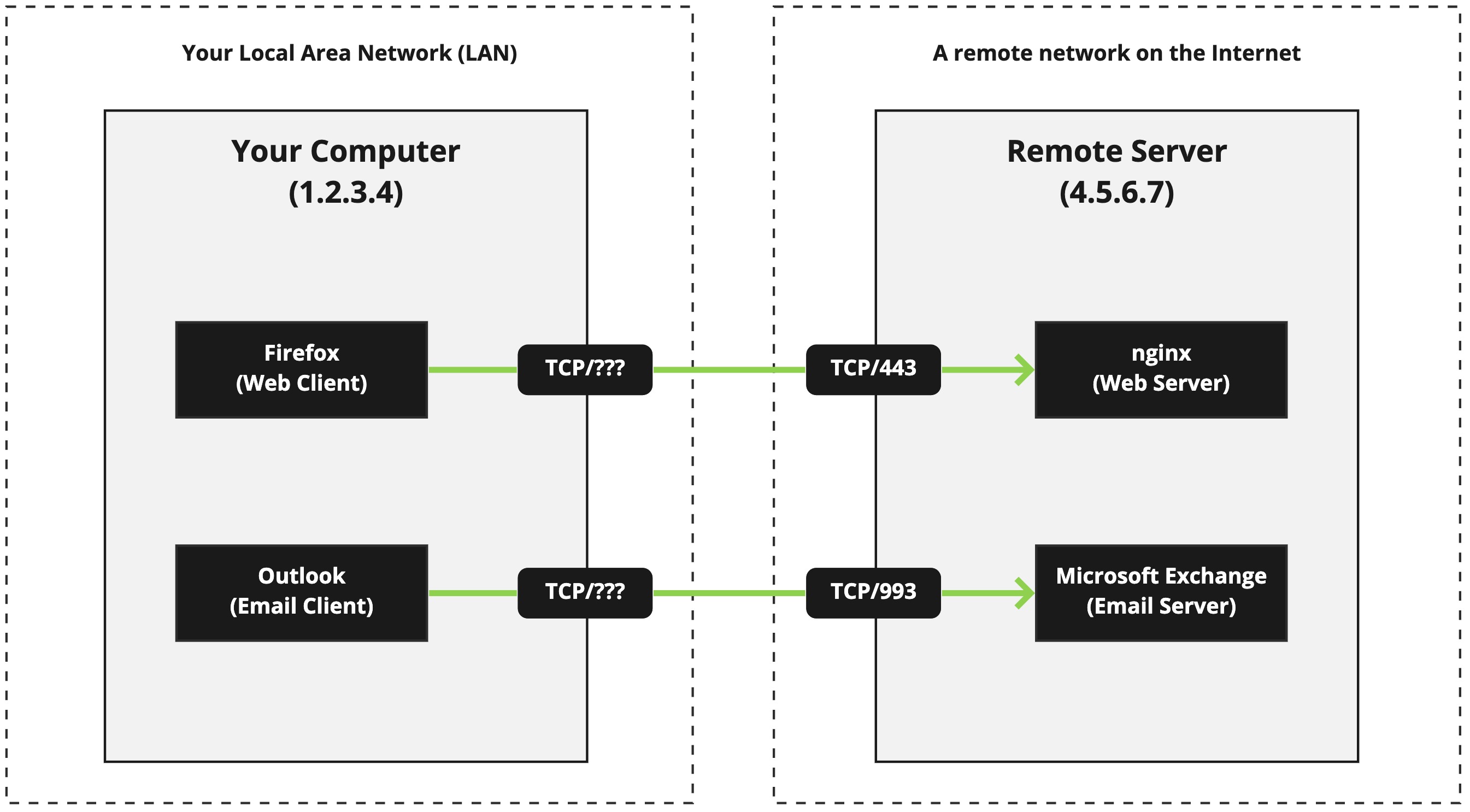
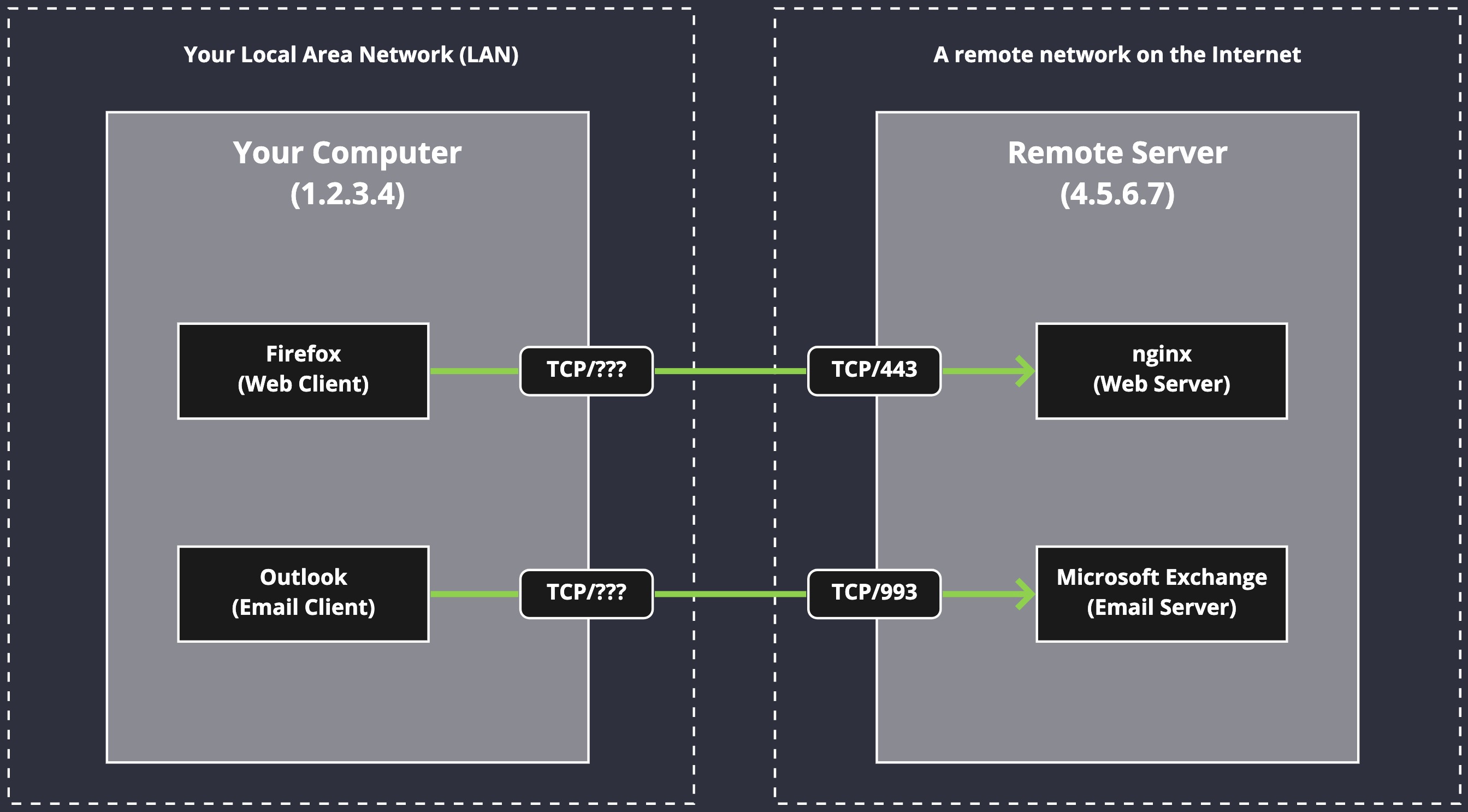
So what are the details we're interested in? There are four (4) pieces of information that are important in a client/server connection:
- The client's IP address (
1.2.3.4) - The client's port number (
???) - The server's IP address (
4.5.6.7) - The server's port number (
443or993)
Three (3) pieces of this information are known to us, but the ??? is an unknown piece of information. That's because on the client's side of the connection there is also a port number. That port number is used for traffic that is returning to the client after the server has something to send it. Without a port number on the client side, the server wouldn't know where to send the data the client originally requested.
This client-side port number isn't really known because it can come from a huge range of ports, and even the range of ports is truly fixed in place - it can change based on the platform the client is on (Windows, macOS, Linux, etc.) The remote server is, of course, given the information in the TCP headers, but there are circumstances when we don't know the port number.
This isn't some mystery or problem we have to solve as engineers, but as you'll see much (much) later on in the AWS section of this course, it does introduce problems as we can't really know the port number and as such, we cannot design network security policies to be perfect.
That's all we really need to know about the client/server model at this point in time.